PySimpleGUI制作百度云图片文字识别软件
python本身无疑是一款非常流行和强大的语言,对于小白来说比较容易上手学习。我也利用网络学习了一些基本的知识,特别是结合阿里云、百度、腾讯或者Azure等云服务商提供的API接口,也切实感受到了
这个语言对解决实际问题的帮助。不过,这些project都是在命令行环境运行的多,为了解决软件的发布问题,只好又了解GUI方面知识。比较几款之后,发现
pysimplegui
非常适合上手。

1.主程序代码如下
import baiduOCR as ocr
import PySimpleGUI as sg
layout = [[sg.Text('请选择要识别的图片'), sg.Text(size=(15, 1), key='-OUTPUT-')],
[sg.Input(size=(100, 1), key='-IN-', readonly=True), sg.FileBrowse('选择文件', file_types=(("jpg", "*.jpg"), \
("gif files", "*.gif"),
("png", "*.png"),
("bmp", "*.bmp")),
key='-FILE-', size=(10, 1))],
[sg.Button('Ok', size=(10, 1), tooltip='点击开始大数据识别图片中的文字'), sg.Button('Exit', size=(10, 1), pad=(0, 10))],
[sg.Output(size=(120, 30), key='-OCROUT-', font=('新宋体, 10'))], [sg.FileSaveAs('另存为:', \
size=(15, 1), pad=(0, 20),\
file_types=(("Text Files", "*.txt"),),\
default_extension='.txt')]]
window = sg.Window('OCR Tool by ', layout)
while True:
event, values = window.read()
filename = values['-FILE-']
if event in (None, 'Exit'):
break
if event == 'Ok':
values['-OCROUT-'] = ocr.ocrlocal(filename)
sg.popup_ok("完成识别")
window.close()
2.baiduOCR模块代码如下
# encoding:utf-8
import requests
import base64
APP_ID = '<- your APPID ->'
API_KEY = '<- your API_KEY ->'
SECRET_KEY = '<- your SECRET_KEY->'
# request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic" #文字识别(高精度版)500次/天
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic" #文字识别(标准版)50000次/天
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' \
+ API_KEY + '&client_secret=' + SECRET_KEY
def ocrlocal(src):
# 二进制方式打开图片文件
f = open(src, 'rb')
img = base64.b64encode(f.read())
global request_url, host
response = requests.get(host)
params = {"image":img}
access_token = response.json()['access_token']
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
result = response.json()['words_result']
for i in result:
print(i["words"])
3.程序完工留念
通过pyinstaller编译打包
pyinstaller -F -w sgTest.py
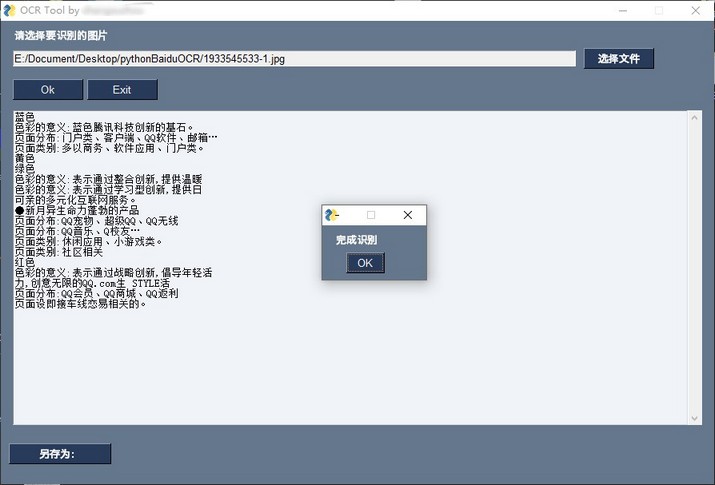
比较麻烦的是,最后保存识别结果的功能还未摸索出来😌
11.23更新 完善保存文件的方法:
# pathlib的方法保存识别结果为txt文件
def save_file_as():
filename = sg.popup_get_file('Save As', modal=True, keep_on_top=True, save_as=True, no_window=True, file_types=(("Text Files", "*.txt"),), default_extension='.txt')
if filename:
file = pathlib.Path(filename)
file.write_text(values.get('-BODY-'))
window['_INFO_'].update(value=file.absolute())
sg.popup_ok('Save Done')
return file
......
if (event == 'Save') and (values.get('-BODY-') != "\n" ):
save_file_as()
if (event == '_INFO_'):
os.system(window['_INFO_'].get())
Read other posts